
> Systems Simplified
Demystifying system architecture for devs and dev-curious alike. Come as you are, build as you go.
In our day-to-day lives, we're surrounded by systems—whether it's the social media app you check every morning, the payment system you use to buy your iced coffee (black), or the cloud infrastructure that stores your critical health or financial information.
A system is a collection of interconnected components that interact to perform specific tasks, enabling users to achieve a desired outcome efficiently and reliably.
The goal of Systems Simplified is to demystify system design by focusing on the essentials—concepts you can use no matter your level of experience. You don’t need a deep background in engineering to follow along! If you're just testing the waters, this discussion will hopefully spark an interest in exploring system design further-or at least give you the answer to "What happens when I go to Google.com?"!
Note: If you're attending a live version of this discussion, you can following along here: Systems Simpified - Live!
Table of Contents
- Introduction
- Setup
- Functional Requirements
- Non-Functional Requirements
- Database Design
- API Design
- Client Interaction
- Addressing Non-Functional Requirements & Scaling the System
- Wrapping Up
Setup
Start with an Idea
The principles discussed below are applicable to nearly any application. To make these concepts more tangible, we’ll use a hypothetical example:
An app that allows users to order a cheap snack and have it delivered by a lil' robot.
We shall call it: Deals on Wheels.

By focusing on this specific scenario, we'll dig in to key system design concepts that you can apply broadly to your own projects or use to prepare for technical interviews.
Tools You'll Need
-
Pencil and Paper: While software tools exist, sometimes the best way to sketch out system architecture and data flow is with simple pencil and paper. This will help you quickly iterate on designs and capture your initial thoughts.
-
Diagramming Tool (Optional): If you prefer digital tools, software like Lucidchart, Draw.io, or Excalidraw(!) can help you create more polished system diagrams.
-
Text Editor or Markdown Tool (Optional): Having a text editor like as VSCode, Sublime Text, or Vim(!) will make it easy to follow along and take notes.
Functional Requirements
Functional requirements define the core features and actions that a system must support; in this case, answering the crucial question:
What does it mean to be Deals on Wheels?
We will focus on three primary features that are central to the operation of our app: Snack Browsing, Order Placement, and Robot Delivery Management.
- Snack Browsing (Read-heavy)
- Users will browse available snacks, which includes categories like sweet, savory, and dietary preferences (e.g., vegan, gluten-free).
This feature will need to handle a high volume of
readrequests as users frequently access and filter snack data.
- Order Placement (Write-heavy)
- Users can select snacks, add them to a cart, and place an order by providing delivery details.
This feature involves multiple
writeactions, such as updating the cart and saving the order to the database when it's confirmed.
- Robot Delivery Management (Write and Read-heavy)
- The system will assign a robot to deliver the user’s order once it has been placed.
- Users can track the robot’s real-time location on a map, which requires frequent reads from the system.
This feature also manages updates related to the robot’s status and location, making this feature both
read- andwrite-heavy.
Out of Scope Features
While important to the overall system, the following features are outside the scope of this discussion:
- User Management (e.g., sign-up, login)
- Payment Processing
- Order Tracking
- Admin/Store Management
- Etc.
Non-Functional Requirements
While functional requirements define what a system does, Non-Functional Requirements describe how a system performs. These are critical to ensuring that the system behaves efficiently, securely, and reliably under various conditions.
For Deals on Wheels, non-functional requirements will ensure that the system can scale to meet user demand, perform efficiently during peak usage, and remain secure while processing orders and delivering snacks. Let's outline the non-functional requirements we will focus on:
-
Availability
- The system should ensure high availability, aiming for minimal downtime. Core features like order placement and robot delivery must be accessible at all times, even during peak usage.
-
Performance
- The system must perform efficiently, with low latency for key actions such as snack browsing, order placement, and real-time robot tracking. Fast response times ensure a smooth user experience, even during high traffic periods.
-
Reliability and Data Consistency
- The system must be reliable, meaning it consistently processes orders, payments, and deliveries without errors. It must also maintain Data Consistency, especially for critical actions like order placement and robot assignments.
Database Design
In system design, it’s essential to begin with the simplest unit of the application: a single piece of data.
By designing the database first, we can establish the foundation upon which the entire system will be built. For simplicity, we’ll focus on the database design for Snack Browsing, the most straightforward of our three functional requirements. This will help illustrate core concepts before we move on to more complex features like order placement or delivery management.
Think of the database as shelves in the snack machine we are putting out of business; holding specific items in a systematic, organized way.
1. Table Diagram(s)
a. Snacks Table
This table will store the essential attributes of each item, providing an answer to the key question:
What does it mean to be a Snack?
Table: `Snacks` | Column Name | Data Type | Description | Constraints | |--------------------|------------|-------------------------------------------|--------------------------------------| | `snack_id` | INT | Unique identifier for each snack | Primary Key, Auto-Increment | | `name` | VARCHAR | Name of the snack | Not Null, Unique | | `description` | TEXT | A brief description of the snack | None | | `category` | VARCHAR | Category of the snack (e.g., Sweet, Salty)| Not Null | | `price` | DECIMAL | Price of the snack | Not Null, Positive Constraint | | `availability` | BOOLEAN | Is the snack available for order | Not Null, Default: TRUE | | `dietary_info` | VARCHAR | Dietary options (e.g., Vegan, Gluten-Free)| None | | `created_at` | TIMESTAMP | When the snack option was added | Default: Current Timestamp | | `updated_at` | TIMESTAMP | Last updated time | Auto-update on modification |
b. Categories Table (Optional)
If we want to allow more flexibility with categories (instead of hardcoding them), we can separate categories into their own table. This makes it easier to add new categories or modify existing ones without changing the structure of the Snacks table.
Table: `Categories` | Column Name | Data Type | Description | Constraints | |--------------------|------------|-------------------------------------------|--------------------------------------| | `category_id` | INT | Unique identifier for each category | Primary Key, Auto-Increment | | `name` | VARCHAR | Name of the category (e.g., Sweet, Salty) | Not Null, Unique |
The Snacks table would then have a foreign key category_id that references the Categories table.
c. Search Index (for optimization)
Since the snack browsing feature is read-heavy, implementing an index on the name, category, and dietary_info columns can improve the search and filtering performance.
CREATE INDEX idx_snack_search ON Snacks (name, category, dietary_info);
This index will allow faster lookup of snacks when users search by name or filter by category or dietary preferences.
2. Capacity Planning
Let’s estimate the storage capacity and plan for constraints:
-
Average Data Per Row (Snack Entry):
- Name: ~50 bytes
- Description: ~200 bytes
- Category: ~20 bytes
- Price: ~8 bytes
- Availability: ~1 byte
- Dietary Info: ~20 bytes
- Timestamps: ~16 bytes
-
Total Storage per Snack: ~315 bytes per snack entry
If we start with around 1,000 snack options in the system, the total storage required would be roughly:
1,000 snacks * 315 bytes ≈ 315,000 bytes (315 KB)
Even with 10,000 snacks, this would only require around 3 MB of storage, which is easily manageable for most systems.
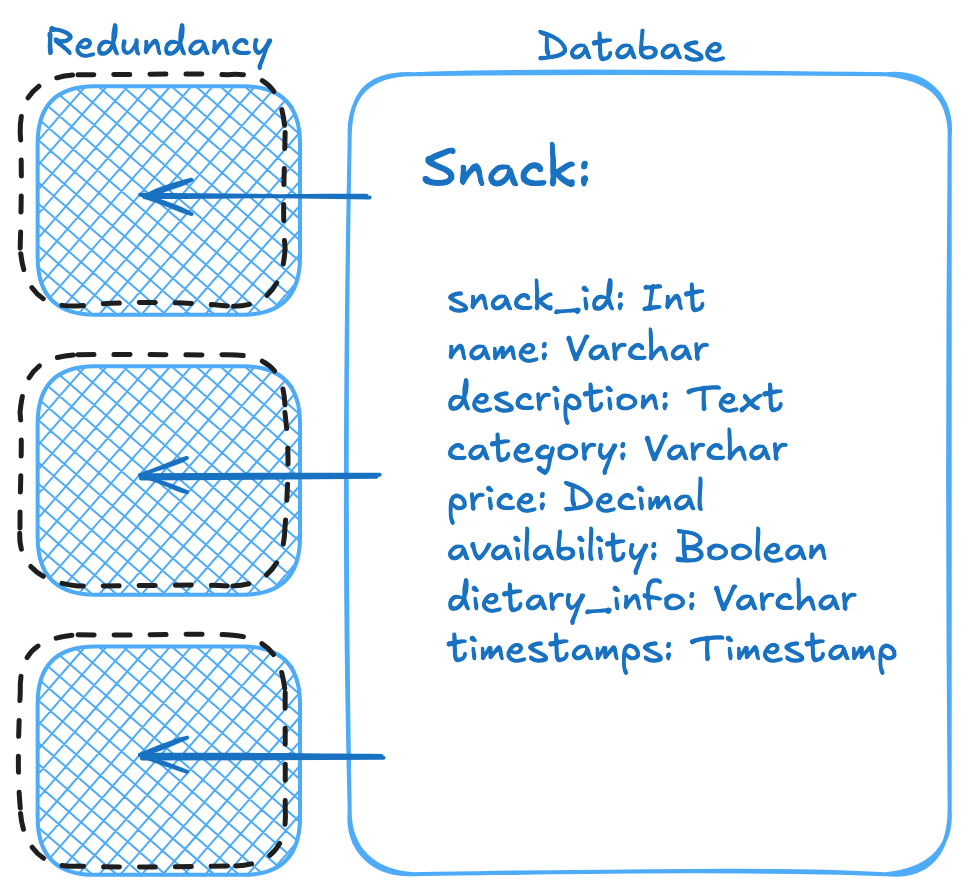
3. Building Database Redundancy for Reliability
To ensure the Deals on Wheels system remains reliable, especially under high traffic or hardware failures, it's important to implement database redundancy. Redundancy involves maintaining copies (or replicas) of the database to protect against data loss, improve performance, and ensure availability.
Some common redundancy methods include:
- Primary-Replica Setup: Writes to a primary database while reads are handled by replicas.
- Failover Mechanism: Automatically promotes a replica if the primary database fails.
- Geographic Distribution: Distributes replicas across different regions for lower latency and improved availability.
By building redundancy into the database system, we ensure reliability and seamless user experience, even during peak demand or unexpected issues.
Database Diagram
BONUS: A Note on NoSQL
While we’re using a relational database design for this tutorial, it’s important to consider that non-relational (NoSQL) databases like MongoDB could also be used, especially if flexibility and scalability are top priorities. In a document-oriented database, each snack could be represented as a JSON-like document. Here's an example:
{ "snack_id": 1, "name": "Chocolate Chip Cookie", "description": "A freshly baked cookie with rich chocolate chips.", "category": "Sweet", "price": 2.99, "availability": true, "dietary_info": ["Vegetarian"], "created_at": "2024-10-10T12:00:00Z", "updated_at": "2024-10-10T12:00:00Z" }
NoSQL databases offer greater flexibility when handling unstructured data or making frequent schema changes, though they may not provide the strong consistency guarantees of relational databases.
API Design
To keep things straightforward, we'll continue focusing solely on the Snack Browsing feature for now. This will give us a solid foundation in API design without diving into the complexities of other features like order placement and robot delivery management. Later, you can apply these same principles to expand the system as needed.
1. Understanding API Design
An API (Application Programming Interface) serves as the gateway to your system.
You can think of an API as the mechanisms of interacting with the Snack Machine (RIP) from or example earlier. In much the same way a customer can enter a code to retrieve a snack but would need a special key to add additional items to the machine itself; clients interact with APIs by making specific requests under pre-defined rules to access or manipulate resources.
2. Define the Actions
For each feature, start by identifying the actions that users or systems need to take. In our Snack Browsing feature, the core action is retrieving a list of available snacks, with options for filtering based on user preferences.
For simplicity, we’ll focus on just a GET request to fetch snack data.
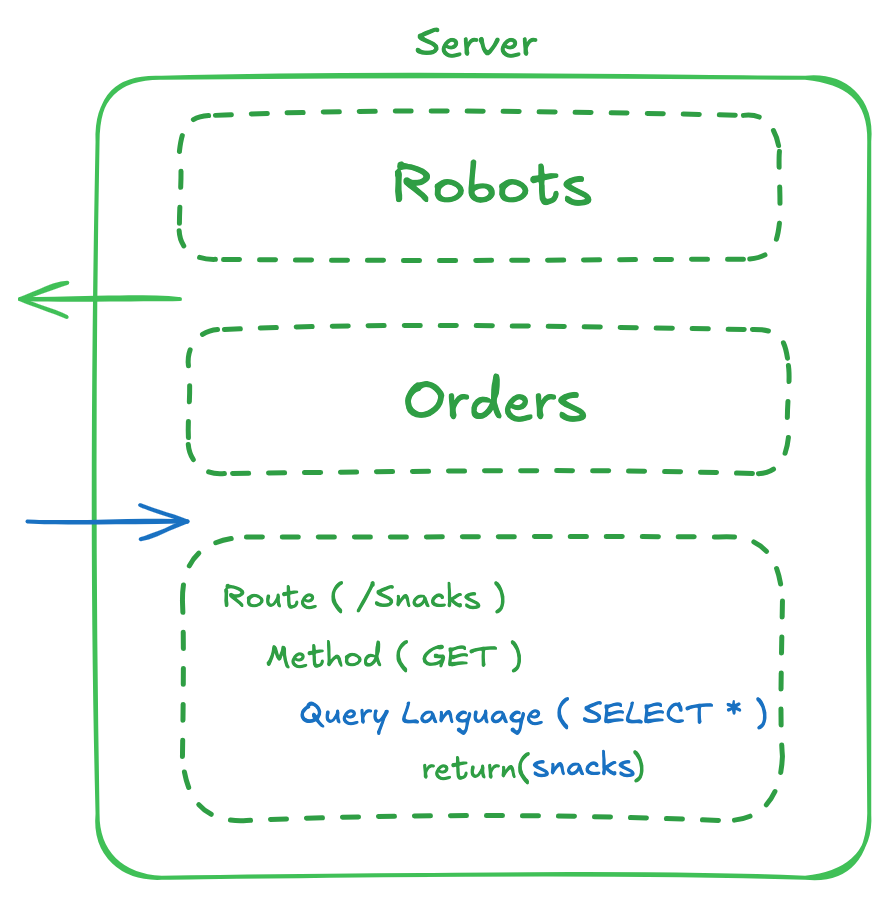
3. Snacks API
The API that supports snack browsing must allow users to read from the system efficiently, handling requests to view snacks, filter by categories, and sort by attributes like price or dietary preferences.
Endpoint: /api/snacks
- Method:
GET - Description: Retrieves a list of available snacks, with optional filters.
- Request Parameters:
category(optional): Filter snacks by a specific category (e.g., Sweet, Salty).dietary_info(optional): Filter by dietary preferences (e.g., Vegan, Gluten-Free).sort(optional): Sort results by price, name, etc.
- Response: A JSON array containing snack objects.
Example Request:
GET /api/snacks?category=Sweet&dietary_info=Vegan&sort=price
Example Response:
[ { "snack_id": 1, "name": "Vegan Chocolate Chip Cookie", "category": "Sweet", "price": 3.99, "availability": true, "dietary_info": ["Vegan"] } ]
4. Framework to Scaffold Your System
When building the API, you'll need to choose a framework that supports your system's architecture. Popular frameworks like Express (Node.js), Django (Python), Rails (Ruby), or .Net (who knows really) provide tools to scaffold and implement the API, making it easier to define routes, handle requests, and interact with your database.
API Diagram
5. Client Interaction
Now that we've designed the API for the Snack Browsing feature, it's time to think about how the client interacts with our system.
Understanding the Client
A client is any entity that interacts with your API. This interaction could be through a user interface, such as a web app, or through other systems that need to retrieve and process data. In this case, the client will act as the "user" browsing our snack catalogue and fetching data from the Deals on Wheels API.
Think of the client as a Snack Machine Catalogue—it doesn’t hold the actual products (snacks) but instead provides representations of them, along with instructions on how to get them. The catalogue tells the user what's available (via the API), and the user selects what they want.
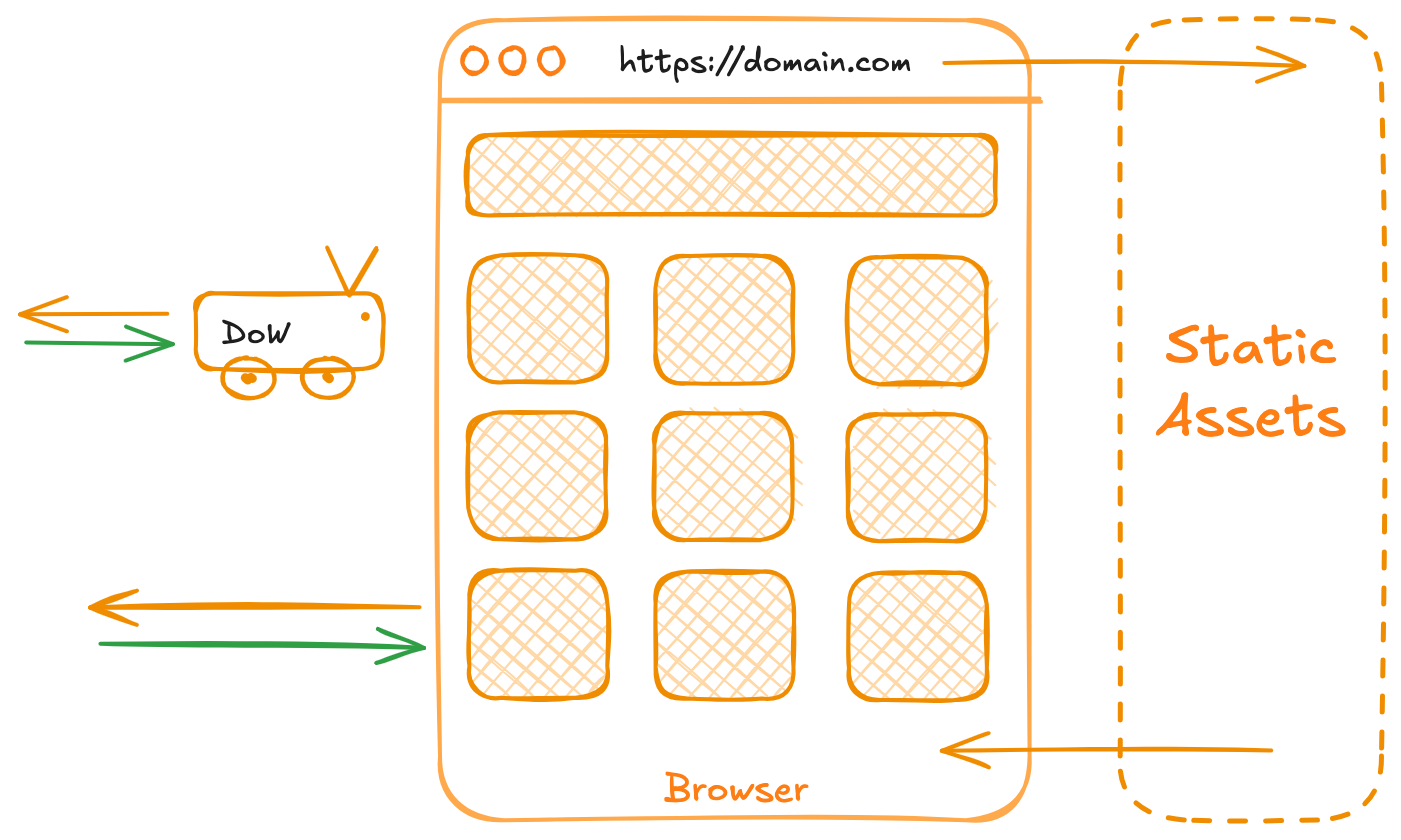
1. Defining Clients for Deals on Wheels
The clients of our system can take various forms. Let's define some of the potential entities that would act as clients for the Deals on Wheels service:
-
Web Browsers + Mobile Apps: The most common form of client for this kind of system. A browser fetches data from the API (e.g., snack availability) and renders the user interface, allowing people to browse and place orders for snacks. The client in this case would be something like a JavaScript front-end (using frameworks like React or Vue) that sends requests to the API.
-
Robots: Even the delivery robots that handle the snack orders are considered clients of the system. While humans interact with the app to place an order, the robot fetches its instructions from the API as well—getting information about which snack to deliver and the address it should head to.
-
Automated Systems: In some cases, third-party services or automated systems may act as clients to the API. For instance, a reporting system that tracks snack sales or a system monitoring inventory could automatically request data from the API.
2. Client-API Interaction Example
Let’s walk through a simple example of how a browser, acting as a client, interacts with the Deals on Wheels API to display snack data.
-
User Action: The user opens their browser and navigates to the Deals on Wheels website.
-
Client Request: The browser (the client) sends a
GETrequest to the/api/snacksendpoint, asking for a list of available snacks. -
API Response: The API responds with a JSON object containing snack data (e.g., Double Chocolate Chip Cookies, RedBull).
-
Client Rendering: The browser takes this data and displays it on the screen, allowing the user to browse through the snacks, apply filters, and select their favorites.
This interaction is repeated whenever the user requests new data (for example, if they apply a filter or refresh the page).
3. Frontend Frameworks for Human Interaction
When building the client interface for humans, we often rely on frontend frameworks to simplify the development process and provide a polished user experience. These frameworks handle rendering the data fetched from the API, managing user interactions, and ensuring the app is responsive and accessible across different devices.
Here are a few popular frontend frameworks that could be used to build the Deals on Wheels interface:
-
React: A widely-used JavaScript library developed by Facebook. It allows developers to build user interfaces with reusable components, making it easy to manage dynamic data (like snack lists) and state changes (like adding a snack to a cart).
-
Vue.js: A progressive framework that is especially good for building interactive user interfaces. It's known for its simplicity and flexibility, making it an excellent choice for small to medium-sized projects like our snack-ordering app.
-
Angular: A full-fledged framework developed by Google, ideal for building complex, scalable applications. It offers out-of-the-box solutions for routing, form handling, and data management.
These frameworks help manage the user experience efficiently, especially when dealing with frequent updates, such as displaying new snack options or tracking robot deliveries in real-time.
Note: These frontend frameworks are only necessary for human-facing clients. Our robots, which interact with the API programmatically, don’t require a frontend and instead function purely through backend communication.
Client Diagram
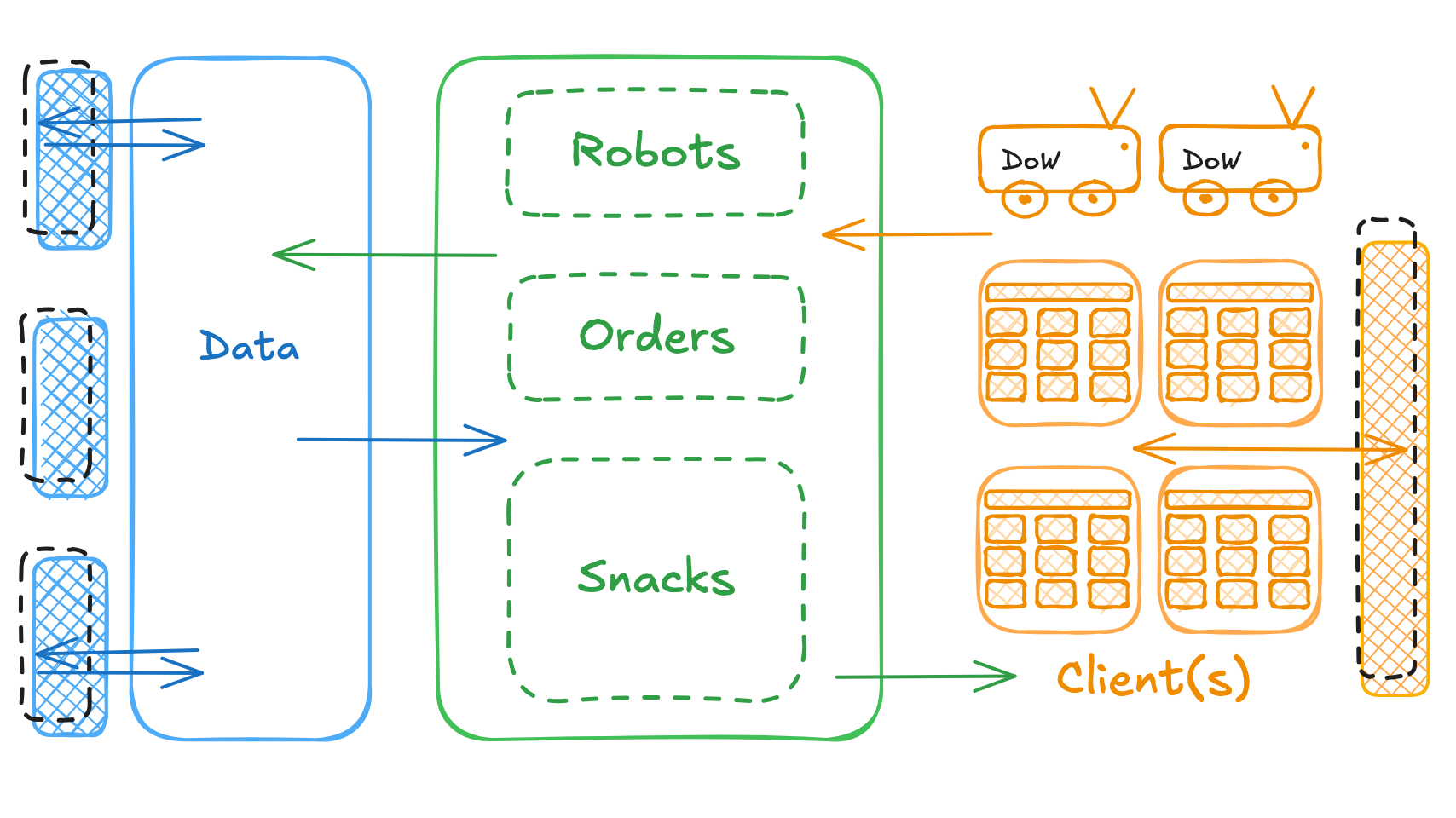
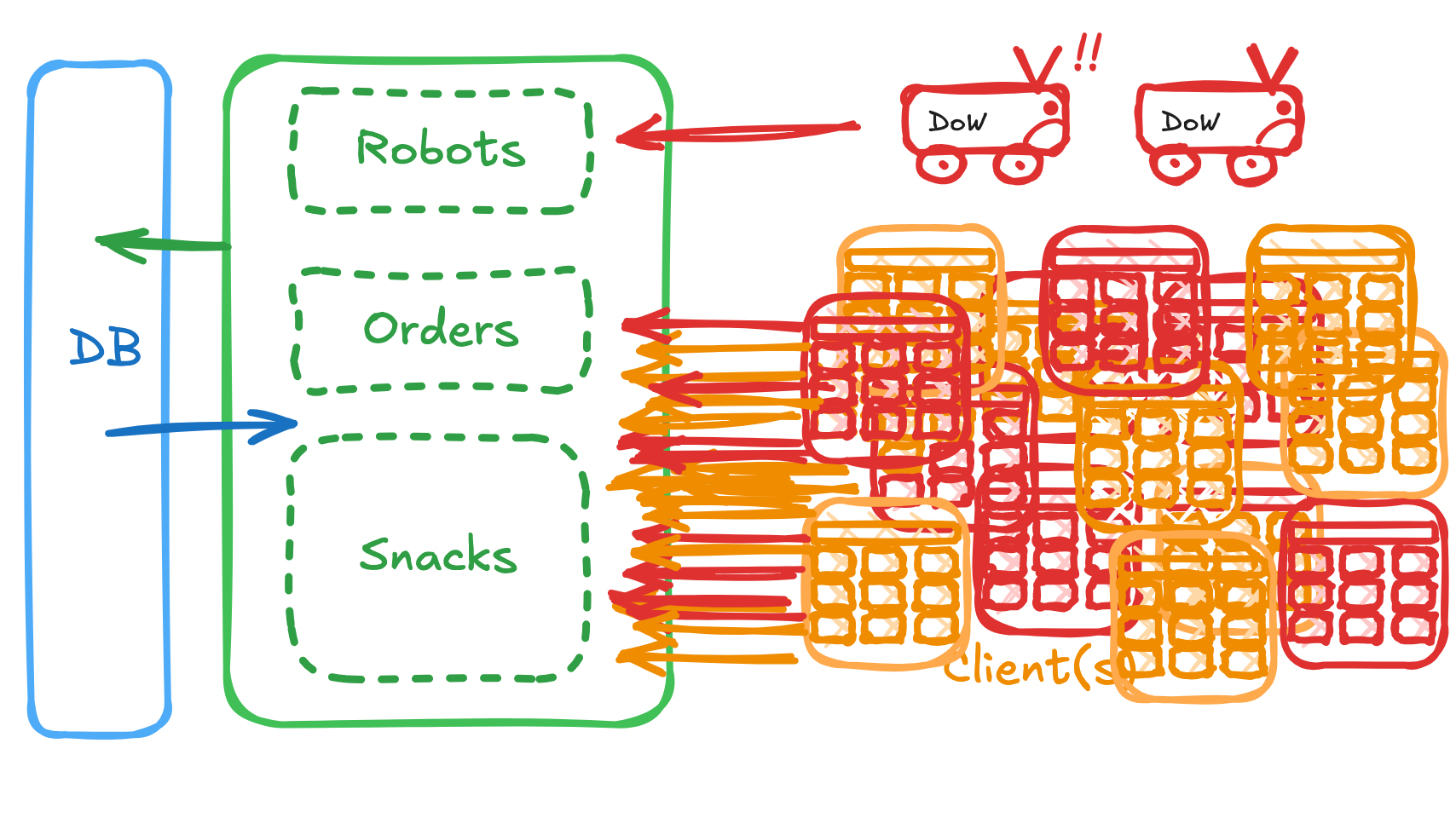
Complete System Overview
Here is a diagram that illustrates the overall system architecture for Deals on Wheels, showing how the client, API, and database interact to support snack browsing, order placement, and robot delivery.
Addressing Non-Functional Requirements & Scaling the System
As we've seen, functional requirements focus on what the system does—like allowing users to browse snacks or placing an order. But as systems grow, we must also address non-functional requirements, which ensure the system performs well under different conditions. These include availability, performance, and reliability—all critical for a smooth user experience.
To illustrate this, let’s imagine a scenario where our system’s non-functional requirements are tested to their limits.
The Problem: A Marketing Scheme Gone Awry
Our marketing team has announced an exciting promotion: “Get any snack for free if you place your order at exactly noon!” Naturally, users rush to the app at noon to get their free snacks, leading to a sudden surge of traffic and requests.
Here’s what happens next:
- Traffic Surge: Thousands of users try to browse snacks and place orders at the same time, leading to a huge spike in both
readandwriteoperations. - Overloaded System: With the flood of simultaneous requests, our system starts to slow down or even crash. The servers struggle to handle the volume of users, and the database can't process orders fast enough.
- Robot Chaos: As orders come in, the robots depend on the system to assign deliveries and track their locations. But with the backend overloaded, the robots can’t get updates, causing delivery delays or failures.
Scaling the System: Introducing Microservices
To handle such a surge in traffic and avoid a system breakdown, we can redesign the system architecture using microservices. In a microservices architecture, each feature (or group of related features) runs as a separate service, communicating through well-defined APIs. This approach offers several advantages, such as isolating failures and scaling specific parts of the system independently.
Here’s how we can break down Deals on Wheels into microservices:
1. Separate APIs for Each Feature
Instead of having a single, monolithic API that handles everything (snack browsing, order placement, and robot management), we can split each feature into its own API:
- Snack Browsing Service: Handles only the
GETrequests for browsing and filtering available snacks. Since browsing is read-heavy, this service can be optimized for quick data retrieval. - Order Management Service: Handles placing and updating orders. This will be write-heavy, so we can scale it independently from the browsing system.
- Robot Delivery Service: Manages robot assignments and tracks delivery statuses, ensuring that robot-related tasks are isolated from other parts of the system.
By splitting each feature into its own service, we reduce the risk of one feature (e.g., snack browsing) overwhelming the entire system and causing a ripple effect that impacts other features (e.g., robot delivery).
2. Further Splitting the Orders System: Read and Write Services
In our marketing promotion scenario, the order system is particularly vulnerable because it must handle both reads (viewing past orders or tracking current ones) and writes (placing new orders). To scale the system even further, we can split the Order Management Service into two parts:
- Order Read Service: Optimized for retrieving order data (e.g., checking the status of a placed order).
- Order Write Service: Handles placing new orders and updating existing ones.
By separating reads from writes, we can independently scale the two services. For example, during the noon rush when everyone is placing orders, we can scale the Order Write Service to handle the influx of new orders, while the Order Read Service remains stable and responsive for users who are just checking the status of their orders.
3. Handling the Traffic Surge with Load Balancing and Autoscaling
To manage the sudden spike in traffic, we can implement the following strategies:
-
Load Balancing: Distribute incoming traffic across multiple servers, ensuring no single server is overwhelmed by the surge in users trying to place orders.
-
Autoscaling: Automatically increase the number of servers or resources when a surge is detected (e.g., around noon during the promotion), and scale down when traffic returns to normal.
These mechanisms ensure that the system remains available and responsive even under heavy loads, and they allow us to gracefully handle unexpected spikes in traffic without affecting the user experience—or the robots' ability to deliver snacks!
4. System Snack In Action
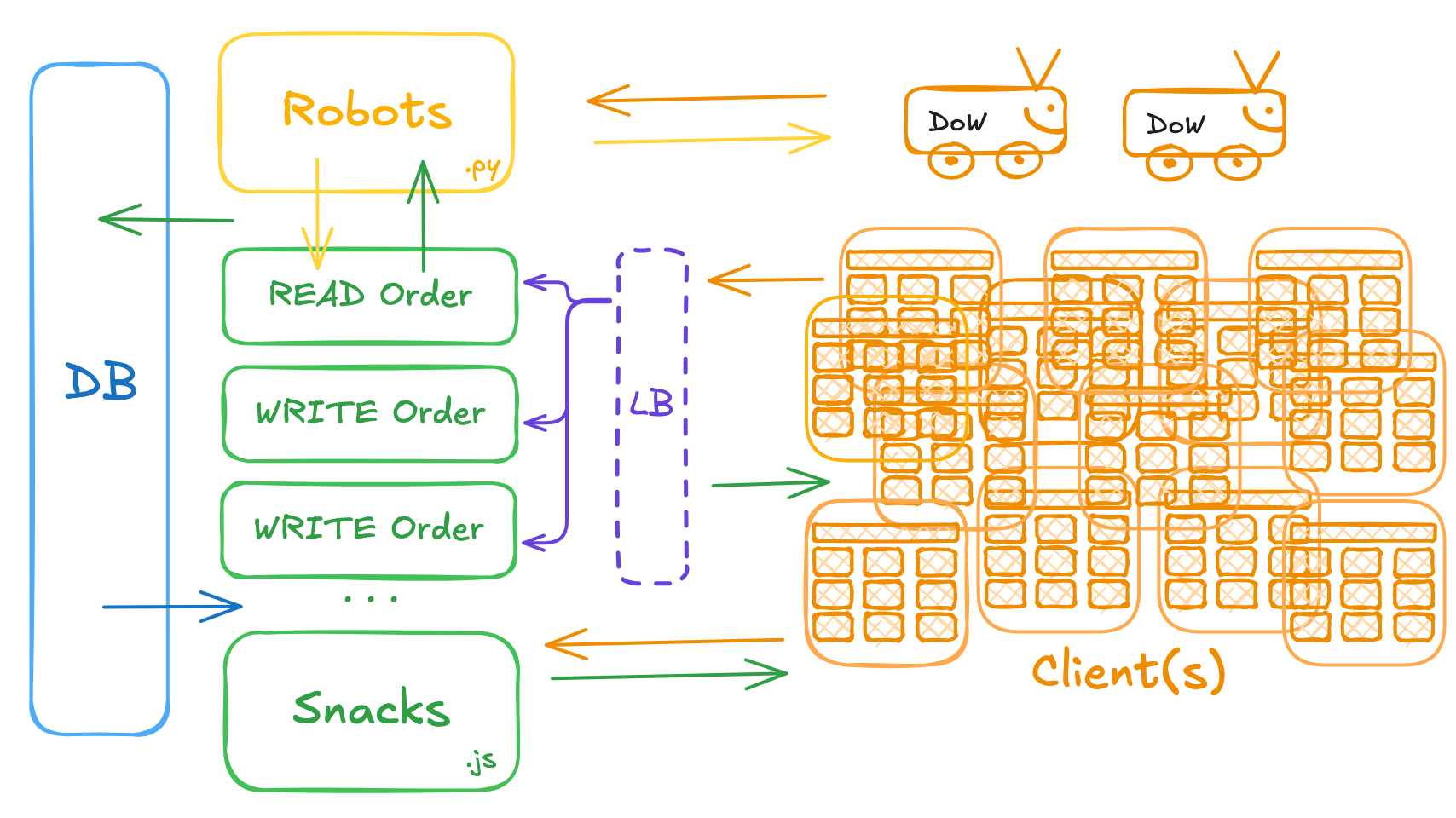
Wrapping Up
And that's it—mostly! In this tutorial, we’ve explored the core concepts of System Design through the lens of our snack-ordering app, Deals on Wheels. From defining functional and non-functional requirements to crafting efficient APIs, we’ve laid the foundation for a scalable, reliable system that can handle the demands of real-world applications.
Here’s a quick recap of the key points:
-
Start with the Essentials: We began by defining our system’s functional requirements, focusing on the core features like Snack Browsing, Order Placement, and Robot Delivery Management.
-
Non-Functional Requirements: Ensuring that the system performs efficiently and remains available even during high-traffic periods, like our marketing promotion, is critical for long-term success. We introduced key non-functional requirements, such as availability, performance, and reliability.
-
Database Design: We designed a relational database to store snack information and introduced the concept of database redundancy to boost system reliability. Implementing redundancy helps ensure the system can recover from failures and continue to serve users without interruption.
-
API Design: We created clear, RESTful APIs to support client interactions, focusing on snack browsing for simplicity. The client (whether a human or robot) interacts with the system through these APIs, fetching and processing data as needed.
-
Scaling with Microservices: To handle the challenges of high traffic (like the promotional surge), we introduced microservices. By separating each feature into its own service, and further splitting the order system into read and write services, we can scale different parts of the system independently, ensuring that one feature’s load doesn’t disrupt the entire system.
The Big Picture
System design is about more than just creating an application—it’s about ensuring that the system performs well at scale, can handle unexpected situations, and continues to deliver a smooth user experience.
Remember, Deals on Wheels is just an example; the concepts we've covered are applicable to many other systems. Whether you're preparing for a technical interview or building your next big project, these are the building blocks you’ll need to succeed.